오늘은 실제 Conv 동작이 일어나게되는 Conv0Layer에 대해서 살펴보겠습니다
module Conv0_Layer #(
parameter DW = 16 ,
parameter WBAW = 4 ,
parameter FBAW = 10 ,
parameter Out_ch = 16
)(
input clk,
input rst_n,
input Active_flag, //Active flag는 Post Conv Top에서 Activation및 Maxpooling이 일어날때도 포함해야하기때문에 이를 포함시켜주는것것
input [ 5 : 0 ] state,
input Conv_start, // Convolution 연산을 시작하도록 지시하는 신호입니다.
output active_done,
input [DW * 16 - 1 : 0 ] Weight_da, //입력 가중치 데이터. 가중치 번들 단위로 16개씩 묶여 있습니다.
input [DW - 1 : 0 ] Pix_da_in, //입력 픽셀 데이터. 폭은 DW (16비트)입니다.
output Weight_rd_en, //가중치 데이터를 읽기 위해 활성화 신호를 출력합니다
output Fmap_rd_en, //Input Featuremap의 data를 읽기위해 활성화 신호
output Conv_done, //Conv 연산이 완료되었음을 나타내는 신호
output [DW * 16 - 1 : 0 ] Cram_da_out_bundle, //연산 결과로 생성된 출력 데이터 bundle
output reg post_enable
);
변수만 봐도 어떤거에 관련되어있는 값인지 잘 알 수 있는데 Cram_da_out_bundle에 대해서 설명하겠습니다
이처럼 Input Featuremap과 Kernel(Weight)가 곱해져 Output Featuremap이 생성됩니다
하지만 저번에 말씀드린것처럼 output Featuremap의 Channel은 Kernel의 Channel을 따라갑니다
이와같이 16개의 Channel에 대해서 수행하도록 만들어져있죠 다시 그림으로 나타내면
16개 다 그리기 귀찮아서 대충 16개라고 봐주세요
DataWidth만큼의 Bit를 가진 OutputFeaturemap 하나의 연산결과가 16개 쭉 있다고 생각하면됩니다
하지만 효율적인 연산, 계산 Flow를위해
이와같이 쭉 연결한다고 보면됩니다
output [DW* 16 - 1 : 0 ] Cram_da_out_bundle, //연산 결과로 생성된 출력 데이터 bundle
그래서 이 코드를 보면 [DW*16-1:0]로 16개의 Channel만큼 생성된것을 볼 수 있습니다
assign Cram_da_out_bundle = {Cram_da_out[ 0 ], Cram_da_out[ 1 ], Cram_da_out[ 2 ], Cram_da_out[ 3 ],
Cram_da_out[ 4 ], Cram_da_out[ 5 ], Cram_da_out[ 6 ], Cram_da_out[ 7 ],
Cram_da_out[ 8 ], Cram_da_out[ 9 ], Cram_da_out[ 10 ], Cram_da_out[ 11 ],
Cram_da_out[ 12 ], Cram_da_out[ 13 ], Cram_da_out[ 14 ], Cram_da_out[ 15 ]};
이와같이 하나의 Data로 묶기 위해 assign으로 선언해주게됩니다. 저 박스 하나하나가 Cram_da_out이 되는거죠
어떻게 Conv가 이루어지는지 알아보겠습니다
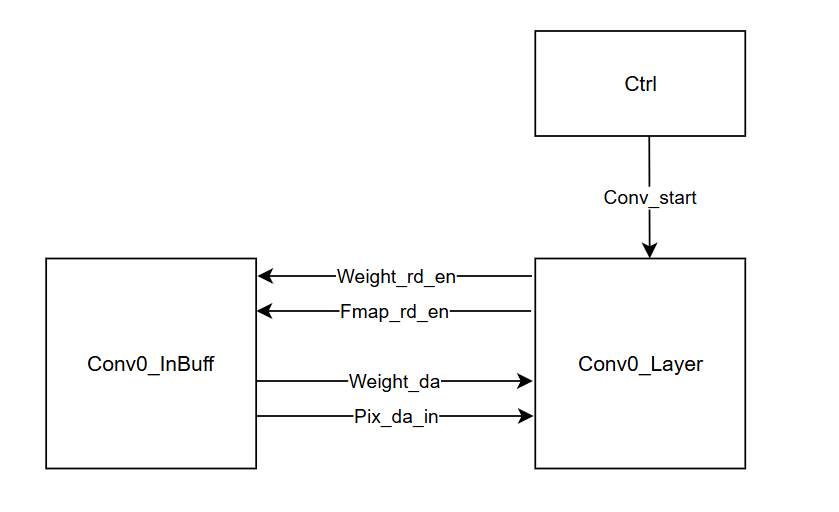
Conv동작원리 최상단에 선언된
input Conv_start, // Convolution 연산을 시작하도록 지시하는 신호입니다.
input [DW * 16 - 1 : 0 ] Weight_da, //입력 가중치 데이터. 가중치 번들 단위로 16개씩 묶여 있습니다.
input [DW - 1 : 0 ] Pix_da_in, //입력 픽셀 데이터. 폭은 DW (16비트)입니다.
output Weight_rd_en, //가중치 데이터를 읽기 위해 활성화 신호를 출력합니다
output Fmap_rd_en, //Input Featuremap의 data를 읽기위해 활성화 신호
해당 구문을 보겠습니다.
이는 Cntrl신호에서 Conv_start신호를 받으면 Weight_rd_en과 Fmap_rd_en 을 High 시켜 Featuremap data와 Weight data를 읽게됩니다.
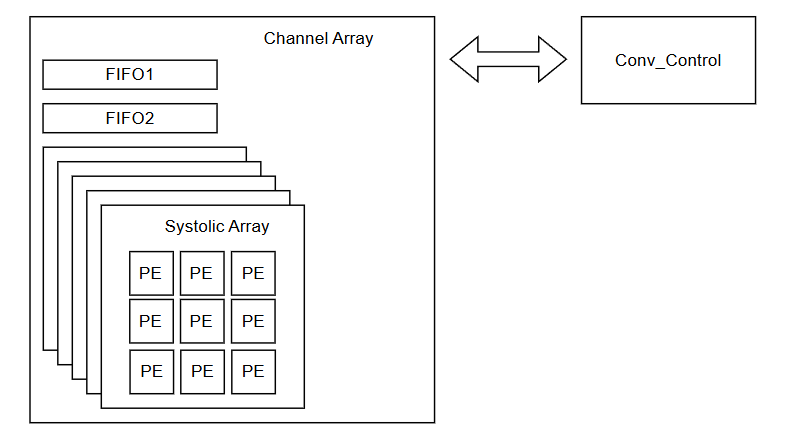
Conv0는 이와같이 구성되어있습니다. 하나하나 살펴보면 Channel Array는 Channel에 대한 Conv 연산을 하게되는곳입니다
해당 MNIST 연산에서는 Featuremap이 Conv 이후에 줄어드는것을 방지하기 위해
Padding 1 Stride 1을 설정하도록 하였습니다. Control 쪽을 살펴보게되면
module Conv_control (
input clk,
input rst_n,
input Conv_start,
input Active_flag,
output reg active_done,
output reg Fmap_rd_en,
output reg [ 1 : 0 ] fifo_wr_en,
output reg [ 1 : 0 ] fifo_rd_en,
output reg Weight_valid,
output reg Weight_rd_en,
output reg Cram_rd_en,
output reg Conv_out_valid,
output reg Conv_done
);
always @ ( posedge clk or negedge rst_n)
begin
if ( ! rst_n) begin
Conv_done <= 0 ;
cnt <= 0 ;
state <= IDLE;
active_done <= 0 ;
end
else begin
case (state)
IDLE : begin
Conv_done <= 0 ;
cnt <= 0 ;
if (Conv_start) begin
state <= K_READ;
end
else if (Active_flag) begin //Active flag 활성화시 Activation을 해줘야하기때문에
state <= Active;
end
else
state <= state;
end
K_READ: begin
if (cnt == 8 ) begin
cnt <= 0 ;
state <= CONV;//3*3 Kernel을 읽어야하기때문에
end
else begin
cnt <= cnt + 1 ;
end
end
CONV: begin
if (cnt == whole_read_cycle + 4 ) begin
cnt <= 0 ;
state <= CONV_DONE; // Conv 동작때 4cycle뒤에 연산이 완료되기 때문에 +4 cycle이후에 Conv_Done
end
else begin
cnt <= cnt + 1 ;
end
end
CONV_DONE: begin
Conv_done <= 1 ; //Conv_done 신호를 외부에 인가하여, 외부 Ctrl 문에 Conv_done 신호를 줘 다음동작을 함
cnt <= 0 ;
state <= Active;
end
Active: begin
Conv_done <= 0 ;
if (cnt == 783 + 3 ) begin // Input Featuremap의 크기가 28*28=784였기때문에 또한 Latency도 포함
active_done <= 1 ;
cnt <= 0 ;
state <= IDLE;
end
else begin
cnt <= cnt + 1 ;
end
end
default : begin
Conv_done <= 0 ;
cnt <= 0 ;
state <= 0 ;
end
endcase
end
end
이렇게 state가 제어되도록하고 state가 K_READ일때
always @ ( posedge clk or negedge rst_n)
begin
if ( ! rst_n) begin
Weight_rd_en <= 0 ;
Weight_valid <= 0 ;
end
else begin
Weight_valid <= Weight_rd_en;
if (state == K_READ) begin
Weight_rd_en <= 1 ;
end
else
Weight_rd_en <= 0 ;
end
end
이처럼 Weight_rd_en을 켜 Weight를 읽을수 있도록합니다. 그렇게 되면 Weight_data가 Channel Array에 인가되도록하는것입니다.
generate
for (i = 0 ;i < 16 ;i = i + 1 ) begin : Systolic
Systolic_Array Systolic_Array (.clk(clk), .rst_n(rst_n), .Pix_da0(fifo_out[ 1 ]), .Pix_da1(fifo_out[ 0 ]), .Pix_da2(Pix_da),
.Wei_da(Weight_da[DW*( 16-i)-1:DW*(15 -i)]), .weight_valid(weight_valid), .Fmap_da(Fmap_da[i]));
end
endgenerate
Channel Array 내부에 있는 Systolic Array를 보게되면
Wei_da가 들어오도록 되어있는데
Conv0_inBuff를보면
assign Weight_da = {Weight_Out[ 0 ],Weight_Out[ 1 ],Weight_Out[ 2 ],Weight_Out[ 3 ],Weight_Out[ 4 ],Weight_Out[ 5 ],Weight_Out[ 6 ],Weight_Out[ 7 ],
Weight_Out[ 8 ],Weight_Out[ 9 ],Weight_Out[ 10 ],Weight_Out[ 11 ],Weight_Out[ 12 ],Weight_Out[ 13 ],Weight_Out[ 14 ],Weight_Out[ 15 ]};
이와같이 선언되어있습니다
즉 MSB가 Channel1에 대한 Weight 값이게 되므로 DW만큼의 Weight값(여기서는 16비트이므로 ffff 같이 하위 4비트를 읽음) 그 Weight 값이
module Systolic_Array #(
parameter DW = 16
)(
input clk,
input rst_n,
input signed [DW - 1 : 0 ] Pix_da0,
input signed [DW - 1 : 0 ] Pix_da1,
input signed [DW - 1 : 0 ] Pix_da2,
input signed [DW - 1 : 0 ] Wei_da,
input weight_valid,
output reg signed [DW - 1 : 0 ] Fmap_da
);
Systolic _Array로 흘러가 Weight 계산일 하게됩니다
pe pe0 (.clk(clk), .rst_n(rst_n), .pixel_data(Pix_da0), .weight_data(Wei_da), .weight_valid(Weight_wr_en[ 0 ]), .back_accum( 32'b0 ), .acc_result(pe_result[ 0 ]));
pe pe1 (.clk(clk), .rst_n(rst_n), .pixel_data(Pix_da0), .weight_data(Wei_da), .weight_valid(Weight_wr_en[ 1 ]), .back_accum(pe_result[ 0 ]), .acc_result(pe_result[ 1 ]));
pe pe2 (.clk(clk), .rst_n(rst_n), .pixel_data(Pix_da0), .weight_data(Wei_da), .weight_valid(Weight_wr_en[ 2 ]), .back_accum(pe_result[ 1 ]), .acc_result(pe_result[ 2 ]));
pe pe3 (.clk(clk), .rst_n(rst_n), .pixel_data(Pix_da1), .weight_data(Wei_da), .weight_valid(Weight_wr_en[ 3 ]), .back_accum( 32'b0 ), .acc_result(pe_result[ 3 ]));
pe pe4 (.clk(clk), .rst_n(rst_n), .pixel_data(Pix_da1), .weight_data(Wei_da), .weight_valid(Weight_wr_en[ 4 ]), .back_accum(pe_result[ 3 ]), .acc_result(pe_result[ 4 ]));
pe pe5 (.clk(clk), .rst_n(rst_n), .pixel_data(Pix_da1), .weight_data(Wei_da), .weight_valid(Weight_wr_en[ 5 ]), .back_accum(pe_result[ 4 ]), .acc_result(pe_result[ 5 ]));
pe pe6 (.clk(clk), .rst_n(rst_n), .pixel_data(Pix_da2), .weight_data(Wei_da), .weight_valid(Weight_wr_en[ 6 ]), .back_accum( 32'b0 ), .acc_result(pe_result[ 6 ]));
pe pe7 (.clk(clk), .rst_n(rst_n), .pixel_data(Pix_da2), .weight_data(Wei_da), .weight_valid(Weight_wr_en[ 7 ]), .back_accum(pe_result[ 6 ]), .acc_result(pe_result[ 7 ]));
pe pe8 (.clk(clk), .rst_n(rst_n), .pixel_data(Pix_da2), .weight_data(Wei_da), .weight_valid(Weight_wr_en[ 8 ]), .back_accum(pe_result[ 7 ]), .acc_result(pe_result[ 8 ]));
이렇게 pe에 선언이 되어있는데, 뭐야 왜 Weight가 다 똑같이 연결되어있어 할수 있지만
generate
for (i = 0 ;i < 9 ;i = i + 1 ) begin
assign Weight_wr_en[i] = (cnt == i) ? weight_valid : 0 ;
end
endgenerate
카운터 마다 weight_valid를 켜줘
Weight값이 PE에 차례로 들어가게 됩니다. 이로써 하나의 Systolic Array에 Weight를 담아, Conv 연산에 필요한 Weight가 저장되는것이죠
generate
for (i = 0 ;i < 16 ;i = i + 1 ) begin : Systolic
Systolic_Array Systolic_Array (.clk(clk), .rst_n(rst_n), .Pix_da0(fifo_out[ 1 ]), .Pix_da1(fifo_out[ 0 ]), .Pix_da2(Pix_da),
.Wei_da(Weight_da[DW*( 16 -i)- 1 :DW*( 15 -i)]), .weight_valid(weight_valid), .Fmap_da(Fmap_da[i]));
end
endgenerate
Channel Array를 보게되면 generate문으로 인해 각자 다른 Channel의 Weight값이 인가되도록합니다
여기까지 Weight가 Conv0_Layer에 어떻게 저장되는것인지 알아보았고 이후 Fmap이 어떻게 인가되는지 알아보겠습니다
Fmap의 동작 먼저 간단한 예시를 들어 설명하겠습니다
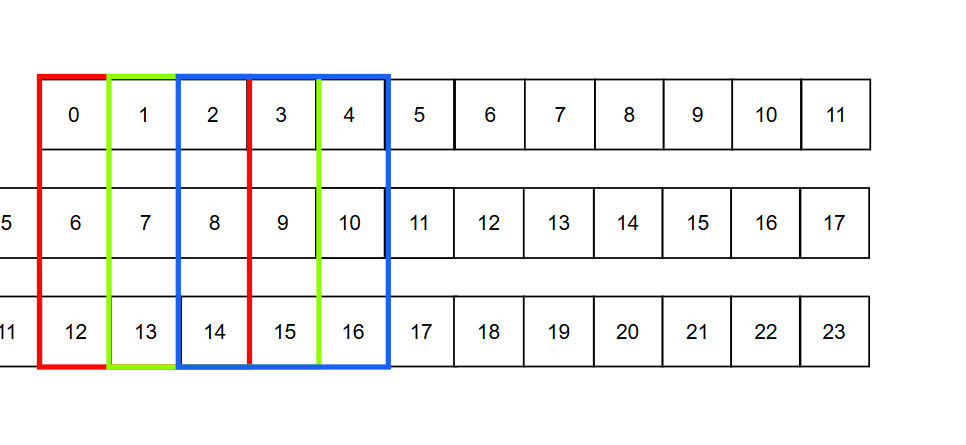
Input Featuremap이 6*6 kernelsize가 3*3 stride 1 padding이 0이라고 하면
이와같이 되어있는 Featuremap일겁니다
이렇게 한 Conv slice(여기선 6)이 되겠죠
이렇게 PE에 저장되어있는 Weight가 있는데 Pix_da로값이 들어가게됩니다 그렇게되면
최상단 FIFO1 중간 FIFO0 아래 Pixda
이렇게 계산이 될겁니다. 2차원이 아니라 Ram은 1차원으로 생각하면되므로 이렇게 쭈우욱 계산되게 되는데
2차원으로생각하면
이렇게 계산과정이 흘러가는 형태라고 볼 수 있습니다
Fmap역시 Conv0_Inbuff에 저장되어있는 Fmap Data를 받아 Pix data로 Channel array에 들어오게됩니다
이전에 포스팅했던것처럼 Fmap은 행단위로 저장되게 됩니다
Fmap data는 Conv_Inbuff에서 Pix_da_in으로 출력되게 되는데 이는 한 픽셀당 값을 의미합니다 한픽셀당 16비트의 데이터가 인가되어있는데,
FIFO FIFO0 (.clk(clk), .rst_n(rst_n), .d_in(Pix_da), .wr_en(fifo_wr_en[ 0 ]), .rd_en(fifo_rd_en[ 0 ]), .d_out(fifo_out[ 0 ]));
FIFO FIFO1 (.clk(clk), .rst_n(rst_n), .d_in(fifo_out[ 0 ]), .wr_en(fifo_wr_en[ 1 ]), .rd_en(fifo_rd_en[ 1 ]), .d_out(fifo_out[ 1 ]));
이처럼 FIFO에 의해 처음 Pix_da가 FiFO에 들어가 다음 FIFO로 들어가게되어,결국
첫번째 행이 FIFO1에 두번째행이 FIFO에 세번째 행이 Systolic Array에 들어가게됩니다
generate
for (i = 0 ;i < 16 ;i = i + 1 ) begin : Systolic
Systolic_Array Systolic_Array (.clk(clk), .rst_n(rst_n), .Pix_da0(fifo_out[ 1 ]), .Pix_da1(fifo_out[ 0 ]), .Pix_da2(Pix_da),
.Wei_da(Weight_da[DW*( 16 -i)- 1 :DW*( 15 -i)]), .weight_valid(weight_valid), .Fmap_da(Fmap_da[i]));
end
endgenerate
Featuremap을 읽으려면 FIFO에 먼저 쓰고 읽어야겠죠
Current_row는 현재 행을 나타내고 Read_cnt는 현재 읽고있는 열을 나타냅니다.
Ram을 읽을때는 행으로 읽는다고했으니, 현재 행에 해당하는 모든 열의 Data를 다 읽고 다음 행을 읽도록 진행합니다. 따라서 Wave form을 보면
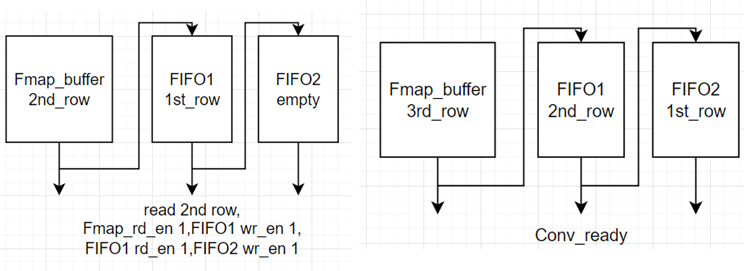
첫번째 CurrentRow를 읽을때 첫번째 행은 Padding 처리 되어있기때문에 Fmap_rd_en을 꺼 Fmap의 data 대신 zero padding 즉 0의 값을 읽도록합니다
따라서 FIFO를 보게되면 Padding때 waddr가 증가하며 해당 행의 data가 읽히고 있는것이 보여지죠
이는 첫번째 행의 data를 FIFO1에 작성한것입니다.
FIFO2는 FIFO1의 data를 받아 첫번째 행의 data를 저장하고 FIFO1은 다음행의 data를 받아 두번째 행의 data를 받게되겠죠
always @ ( posedge clk or negedge rst_n)
begin
if ( ! rst_n) begin
fifo_wr_en <= 0 ;
end
else begin
if (state == CONV) begin
if (cnt >= 0 && cnt < whole_read_cycle) begin
if (current_row == 0 ) begin
fifo_wr_en[ 0 ] <= Fmap_rd_en || padding;
fifo_wr_en[ 1 ] <= 0 ;
end
else if (current_row == 1 ) begin
fifo_wr_en[ 0 ] <= Fmap_rd_en || padding;
fifo_wr_en[ 1 ] <= fifo_rd_en[ 0 ];
end
else if (current_row == slice_size_reg + 1 ) begin
fifo_wr_en[ 0 ] <= 0 ;
fifo_wr_en[ 1 ] <= 0 ;
end
else begin
fifo_wr_en[ 0 ] <= 1 ;
fifo_wr_en[ 1 ] <= 1 ;
end
end
else begin
fifo_wr_en <= 0 ;
end
end
else begin
fifo_wr_en <= 0 ;
end
end
end
이처럼 첫번째행을읽을때는 wr_en[1],즉 FIFO2의 write enable을 꺼줘 FIFO1에만 data가 읽히게두고
두번째행을 읽을때는 wr_en을 모두 켜줘 FIFO 1, 2 에 data가 모두 적힐수있도록합니다
이와같이 Flow가 구성되는데 실제 Conv 계산이되는 systolic Array를 보면
FIFO FIFO0 (.clk(clk), .rst_n(rst_n), .d_in(Pix_da), .wr_en(fifo_wr_en[ 0 ]), .rd_en(fifo_rd_en[ 0 ]), .d_out(fifo_out[ 0 ]));
FIFO FIFO1 (.clk(clk), .rst_n(rst_n), .d_in(fifo_out[ 0 ]), .wr_en(fifo_wr_en[ 1 ]), .rd_en(fifo_rd_en[ 1 ]), .d_out(fifo_out[ 1 ]));
genvar i;
generate
for (i = 0 ;i < 16 ;i = i + 1 ) begin : Systolic
Systolic_Array Systolic_Array (.clk(clk), .rst_n(rst_n), .Pix_da0(fifo_out[ 1 ]), .Pix_da1(fifo_out[ 0 ]), .Pix_da2(Pix_da),
.Wei_da(Weight_da[DW*( 16 -i)- 1 :DW*( 15 -i)]), .weight_valid(weight_valid), .Fmap_da(Fmap_da[i]));
end
endgenerate
이처럼 구성되어있습니다. 즉 Pix_da0가 첫행 Pix_da1이 두번째행 Pix_da 2가 세번째행이게되는데
Fifo_out이 모든 행의 data를 보내려면 slice_size+1만큼 기다려야 한 행의 data가 온전히 나오게됩니다
따라서 FIFO1 첫번째 행의 data 즉 padding의 data가 나오면 FIFO0에서는 두번째행의 data가 나오고 그때 Pixda2는 세번째행의 data를 내보내게됩니다
이처럼 구성되게 되는데 실제 Conv가 일어날때는 하얀색 박스일때므로 Pix_da0에 첫번째행 Pix_da1에는 두번째행 Pix_da2에는 세번째 행의 data가 있도록 되어있습니다
그결과 Fmap data가 되게되는데
assign Fmap_da_out = {Fmap_da[ 0 ],Fmap_da[ 1 ],Fmap_da[ 2 ],Fmap_da[ 3 ],Fmap_da[ 4 ],Fmap_da[ 5 ],Fmap_da[ 6 ],Fmap_da[ 7 ],
Fmap_da[ 8 ],Fmap_da[ 9 ],Fmap_da[ 10 ],Fmap_da[ 11 ],Fmap_da[ 12 ],Fmap_da[ 13 ],Fmap_da[ 14 ],Fmap_da[ 15 ]};
이와같이 선언을 하여 Channel에 대해서 나타내주고 Fmap들이
generate
for (j = 0 ;j < Out_ch;j = j + 1 ) begin : Conv_out
assign Conv_data[j] = Fmap_da_out[DW * ( 16 - j) - 1 :DW * ( 15 - j)];
end
endgenerate
이와같이 모이게되어 Conv_data가 되도록합니다 그것이 Conv_mem의 메모리에 들어가게되는데
//Conv_control
always @ ( posedge clk or negedge rst_n)
begin
if ( ! rst_n) begin
Conv_out_valid <= 0 ;
conv_cnt <= 0 ;
end
else begin
if (state == CONV) begin
if (cnt >= (slice_size + 2 ) * 2 + 5 ) begin
if (conv_cnt == slice_size_reg + 1 )
conv_cnt <= 0 ;
else
conv_cnt <= conv_cnt + 1 ;
if (conv_cnt >= 0 && conv_cnt < slice_size_reg)
Conv_out_valid <= 1 ;
else
Conv_out_valid <= 0 ;
end
else
Conv_out_valid <= 0 ;
end
else begin
conv_cnt <= 0 ;
Conv_out_valid <= 0 ;
end
end
end
Conv_control에 따라 Conv_out_valid를 받게되면 Conv_mem의 wr_en이 on이되어 Fmap의 data가 쓰여지게됩니다. 여기서 쓰여진 Fmap의 data는 Pooliing 및 Activation에서 필요하게되는데 그것은 차후에 다루도록 하겠습니다.
따라서 결과적으로 Convolution 결과들이 모여
assign Cram_da_out_bundle = {Cram_da_out[ 0 ], Cram_da_out[ 1 ], Cram_da_out[ 2 ], Cram_da_out[ 3 ],
Cram_da_out[ 4 ], Cram_da_out[ 5 ], Cram_da_out[ 6 ], Cram_da_out[ 7 ],
Cram_da_out[ 8 ], Cram_da_out[ 9 ], Cram_da_out[ 10 ], Cram_da_out[ 11 ],
Cram_da_out[ 12 ], Cram_da_out[ 13 ], Cram_da_out[ 14 ], Cram_da_out[ 15 ]};
번들로 구성되어 다음 PostConvlayer에서 이용되도록합니다
+
Maxpooling 시 Cram에서 읽는방법 cram에서 data를 읽을때 저장은
이처럼 한 행씩 저장하게 됩니다
하지만 Maxpooling은
이와같이 Maxpooling에 이루어져야하는데 어떻게 해야 그렇게 할수있을까요? 바로 읽는방법에서 차이가 있습니다
reg [ 1 : 0 ] Cram_rd_cnt;
reg [ 3 : 0 ] Cram_row_cnt;
always @( posedge clk or negedge rst_n)
begin
if ( ! rst_n)
begin
Cram_raddr <= 0 ;
Cram_rd_cnt <= 0 ;
Cram_row_cnt <= 0 ;
end
else
begin
if (Cram_rd_en)
begin
if (Cram_raddr == Conv0_slice ** 2 - 1 )
begin
Cram_raddr <= 0 ;
end
else
begin
if (Cram_rd_cnt == 3 )
begin
if (Cram_row_cnt == 13 )
begin
Cram_row_cnt <= 0 ;
Cram_raddr <= Cram_raddr + 1 ;
end
else
begin
Cram_raddr <= Cram_raddr - Conv0_slice + 1 ;
Cram_row_cnt <= Cram_row_cnt + 1 ;
end
end
else if (Cram_rd_cnt == 1 )
begin
Cram_raddr <= Cram_raddr + Conv0_slice - 1 ;
end
else
begin
Cram_raddr <= Cram_raddr + 1 ;
end
end
Cram_rd_cnt <= Cram_rd_cnt + 1 ;
end
else
begin
Cram_raddr <= 0 ;
Cram_rd_cnt <= 0 ;
Cram_row_cnt <= 0 ;
end
end
end
처음 이걸 보면 무슨말 하는지 모를수 있습니다 다시 정리해보면
이와같이 정리할수있습니다. 이걸봐도 모를수도 있습니다
그림으로 설명하면
이와같이 읽기동작이 나타나게됩니다
rd_cnt는 열을 읽는동작이고 Row_cnt는 행을 읽는 동작입니다
그렇게되면 이와같이 동작한다는것을 볼 수 있습니다