[CNN] CNN in Verilog 1
YOLO Series나 다른 CNN module을 보면 Convolution Network가 자주 사용되는것을 볼 수 있다.
기본적으로 물체를 탐지하는 Object detection을 보면

간단한 도식도로 이런식으로 생겼다.
Input Image가 Convolution Network를 거쳐 Output Image를 생성한다
솔직히 나는 처음배울때 전혀 와닿지 않았다. Convolution이 뭐고 input image가 뭐고 output image가 뭔데....
InputImage는 원본사진이고 Conv Network를 거쳐 OutputImage로

이와같이 객체를 탐지해서 Output Image가 나오게된다
이를 Verilog로 설계하는것은 매우복잡하기때문에 기초부터 공부하여 설계를 해보도록 하자
1. Convolution이란

Input featuremap이라는 data가 들어오게 된다. Input Featuremap은 저런식으로 Data를 갖게 되어있는데 각 이미지들은 픽셀값마다 저런 숫자를 갖고있다. 숫자마다 빛의 세기를 나타내고
Image들은 RGB 채널로 구성되어있다
그래서 초기 Input image는 3개의 Channel로 구성되어있다.
Convolution은 이와같이 Filter들과 각채널들마다 input image들의 곱하고 각채널들의 값을 모두 더해서
하나의 Output channel을 구성하게된다

이런식으로 구성되는데 Inputchannel은 3개의 Channel이고 Output Channel은 3개의 Channel을 갖는다
Conv Channel은 총 9개니까 9개의 Channel이 아니다.
InputImage의 Channel의 맞는 쌍인 Conv channel이 1개의 Conv channel임을 알아야 한다

보통 이와같은 모식도를 갖기때문에 Conv Channel에 대해 헷갈리곤하는데 이와같이 구성되게 된다
Convolution은 Verilog로 어떻게 구성될까?
2.PE
Pe는 (Processing Element)로 Conv의 기본연산인 Weight를 곱하고 더하는 과정을 수행하는 것이다

기본 모듈은 이와같이 구성되는데
Pix값은 Input featuremap의 Input이고 Weight는 가중치에 해당하는 값인데,
주로 Weight를 먼저 받아 Weight_reg에 저장해놓고 Pix data가 들어오게되면 두 값이 곱해져 Convolution 연산을 하게된다
이후 back_acc는 그 이전 PE의 값에 해당하는 값이다
해당값을 보게되면 같은 Channel끼리 곱해지게 되고, Channel1 안에 Conv Weight에서 Channel 1_1 ,1_2,1_3이 있는데 Input Featuremap과 곱해져, 최종 Output을 만들게 된다
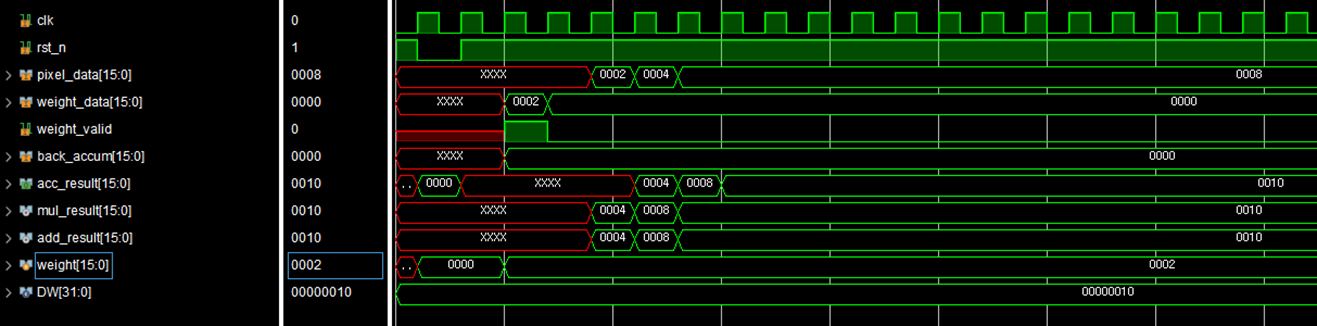
Waveform을 보면
해당 모듈은 단일 PE에 대한 모듈이다
Pixel_data가 2 4로 들어오게되면 저장되어있던 Weight_data 2와 곱해져 4와 8이라는 결과를 생성하게 된다
여기서는 back_accum의 값을 0으로 정의했기때문에 최종 acc_result가 4와 8로 결정되는 것을 볼 수 있다.
3. 1Dimension Conv, Systolic Array

이와같이 계산을 하는 모듈을 생각해볼수있다


총 3개의 Result가 이렇게 결과가 나오게된다
이처럼 행렬 연산이나 컨볼루션 연산을 나타내며 이를 Systolic Arrray라고 한다

이와같이 구성되어있는데

Timing diagram은 이와같다
첫번째 PE에는 Weight 1에 대한 값이 고정되어있다
따라서 cycle마다 모든 PE에 동일한 Pix data 값이 들어오게 된다
1. 첫번째 Cycle에는 PE0에는 Weight 1의 값과 Pix data 1의 값이 모든 PE에 들어와 곱 연산을 거치게 된다
곱연산을 하는데 한 Cycle이 소요되니 한 Cycle뒤 PE0에는 D1xW1의 값이 존재하게 되는것이다
그 다음 사이클을 보게 되면
PE0에 있던 값이 PE1으로 들어가게 되는데 이전에 봤던 Diagram에서 볼수 있는 Back_acc가 이와같은 값이다
PE1에서는 Weight 2가 고정되어있는 상태로 Data가 들어오게 되는데 Pix 값으로 2의 값이 들어오기 때문에 D1*W1+D2*W2가 되게 된다
이값이 또 PE3로 넘어가게되고 최종 결과가 Fmap_da로 나오게된다
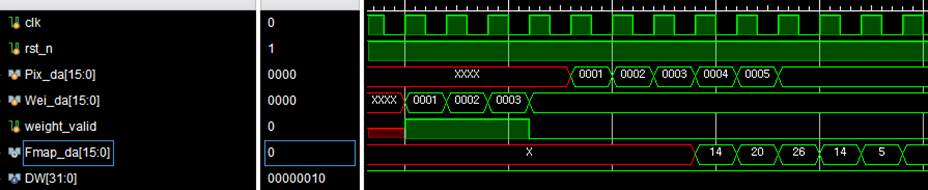
최종 Fmap data가 나오기까지 총 4Clock뒤에 Fmap data가 나오게 되고 , 3Cycle만 유효한 data이게된다, 왜나하면 뒤에있는 14와 5는 D4와W1이 곱해진값 +D5와 W2이 곱해진값 + D6와 W3의 곱해진값의 결과인데 여기서는 D6의 값이 없으므로 유효한 data가 아니다
4.2Dimension Conv,Systolic Array
위는 1차원행렬의 기본적인예시였고, 실제 Convolution 연산은 보통 2차원 행렬로 계산하게된다
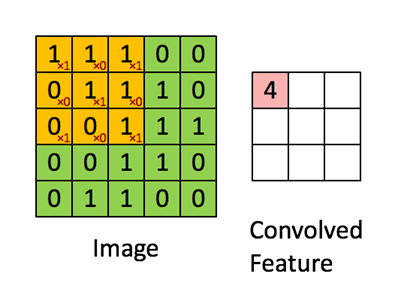
이와같이 Input Image에 Weight값이 곱해져나가면서 Output Featuremap을 계산하게된다

이와같이 생각할수있는데
Stride(Weight가 움직이는 거리) =1 , Padding ( Input featuremap에 0을 삽입하여 계산하는것)=0
이라고 생각해보자

이와같은 Diagram을 생각해볼수 있을것이다
PE에는 Weight값이 저장되어있고 0부터 8까지이므로 Kernel(=Weight)Sizse는 3*3 Kernel일것이다
PE의 012,345,678을 묶어 1Dimension Conv로 생각할수 있게 되고 위와 같은 형식으로 계산되게 된다

이와같이 코드를 보면 1Dimension의 Pix_data는 같은 값이 들어오므로 총 3개의 Row(행)이 필요하게 된다
Weight_da는 Weight는 3*3의 kernel size이므로
총 9개의 Weight_wr_en을 선언해준다 이는 PE에 각기 다른 Weight값을 넣어주기 위함이다


이와같이 Waveform을 확인할수있는데 원래 4Cycle만에 유효값이 나왔으나
이 그림을 보게되면 위 두 Row의 PE의 덧셈에서 1Cylce 또한 아래 PE의 덧셈에서 1Cycle이 추가되어
6Cycle뒤에 유효한 값이 나오게 된다
5.Use FIFO 2Dimension Conv

허나 이렇게 F_map Buffer를 사용하게되면 총 9개의 값을 저장해야하는 Buffer를 사용해야한다
하지만 이렇게 되면 Fmap Buffer의 재사용성이 떨어져 Resource를 많이 잡아먹게 되는 결과를 초래하게된다
따라서 FIFO를 사용하여 한열씩 Fmap_buffer에 넣어주게된다

이런식으로 구성되도록하게한다
왜이렇게 하는지 의문이 들수도 있는데
Fmap_data는 기본적으로 YOLO v2의 경우 416*416=173,056 의 image가 들어오게된다. 이런 이미지들이 한두개가 아니라 9000개이상의 data가 들어오기때문에 많은 자원이 소요될 수 있다.

이렇게 선언해주면 병렬적으로 수행해주기위해 Fmap의 data의 첫번째 열을 FIFO2에 저장하고
Fmap data의 두번째열을 FIFO1에 저장하고
Fmap data의 세번째열을 바로 Systolic array에 인가해주면된다
원래 FIFO가 없었다면 3열을 모두 저장하는 Buffer의 크기가 필요했지만, 한열만 저장하는 Buffer만 사용해줄수 있도록한
다

모든 값들이 저장되어있다면 첫번째 Convolution이 시작된다.

이후 한열씩 내려가며 마치 Kernel이 이동하는것처럼 보이지만
실제로는 Kernel은 고정되어있고
Fmap data의 열이 하나씩 내려가며 Convolution 연산을 하게되는것이다
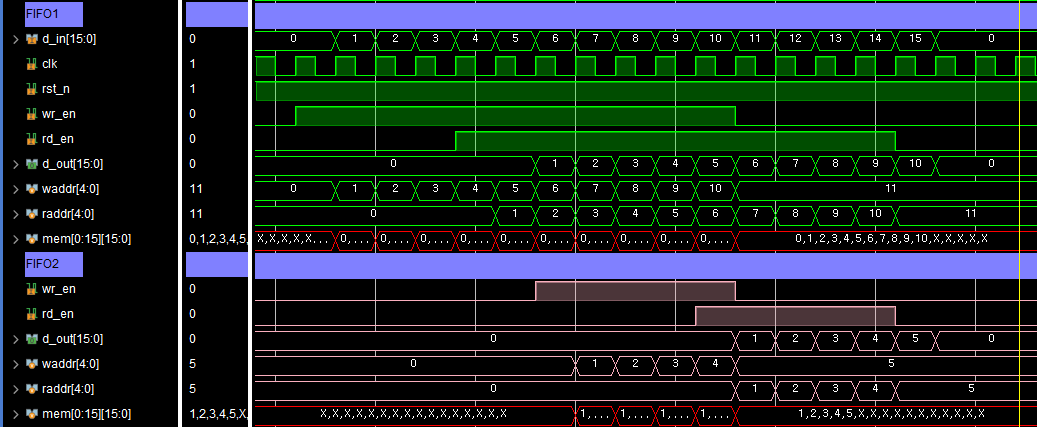
두번째 열이 저장되는 FIFO1을 보자,
FIFO2에 1,2,3,4,5의 정보가 저장이 되어야하므로 FIFO1의 1,2,3,4,5의 정보가 저장되었을때
FIFO1의 d_out이 FIFO2의 d_in과 연결되어있으므로 1,2,3,4,5의 정보만 d_in을해주고 나머지는 wr_en을 Low로 바꿔 정보가 들어오지 않도록한다
즉 FIFO2에는 12345
FIFO1에는 6789A(Hexdecimal)
이 저장되록하는것이다

Convolution 계산결과 역시 동일하다